

 From what data can we learn concepts such as objects, actions, and scenes? Recent studies on zero-shot, one-shot, and few-shot learning have shown the effectiveness of collaboration between computer vision and natural language processing. This workshop promotes deeper and wider collaboration across many research fields to scale-up these studies. With the common theme Learning Concepts we hope to provide a platform for researchers to exchange knowledge from their respective backgrounds.
From what data can we learn concepts such as objects, actions, and scenes? Recent studies on zero-shot, one-shot, and few-shot learning have shown the effectiveness of collaboration between computer vision and natural language processing. This workshop promotes deeper and wider collaboration across many research fields to scale-up these studies. With the common theme Learning Concepts we hope to provide a platform for researchers to exchange knowledge from their respective backgrounds.

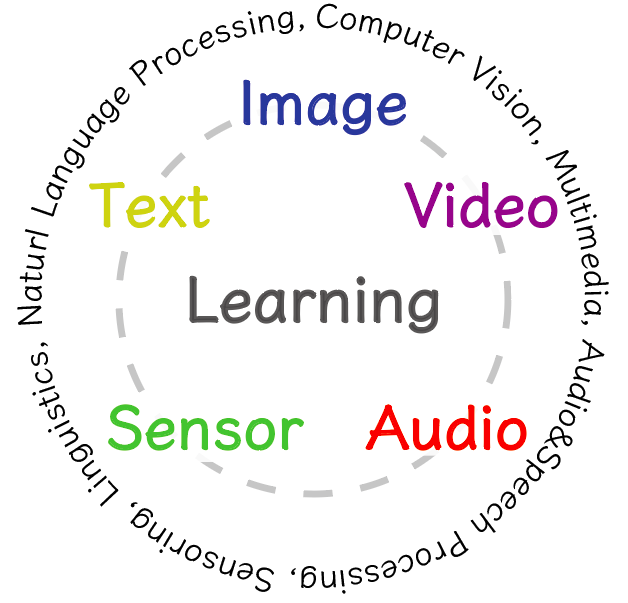
We call papers of the following 5x5 topics for learning concepts (objects, actions, scenes etc) from various types of data.
| · Few-/Low-/k-Shot Learning |
 from
from
| Image Data |
|---|---|---|
| · One-Shot Learning | Video Data | |
| · Zero-Shot Learning | Text Data | |
| · Cross-Domain Learning | Audio Data | |
| · Meta Learning | Sensor Data |
This scope includes (but not limited to)
| · Zero-Shot Learning for Object Detection from Images |
|---|
| · Few-Shot Learning for Action Recognition from Videos |
| · One-shot Learning for Scene Understanding from Images with Texts |
| · Meta Learning for Video Captioning |
| · Joint Image-Text Embeddings for Cross-Domain Learning |
| · Joint Audio-Visual Embeddings for k-Shot Classification |
| · One-Shot/Imitation Learning from Video Data with Sensory Inputs |
and the other combinations of learning frameworks and tasks. The organizers will also provide a new challenging dataset, namely Few-Shot Verb Image Dataset with images of 1,500 verb concepts. This is a part of the Large-Scale Few-Shot Learning Challenge to create a large-scale platform for benchmarking few-shot, one-shot, and zero-shot learning algorithms. Papers using this dataset are also acceptable through the regular review process (This is optional).

October 27th (the same venue as ICCV 2019 in Seoul, Korea)
9:00 - 9:10 Welcome
9:10 - 10:10 Oral Session (15 mins x 4 Full Papers)
10:10 - 10:30 Coffee Break
10:30 - 11:15 Invited Talk: "Localizing concepts, the few-shot way" by Cees Snoek
11:15 - 11:30 Spotlight Session (1 min x 10 Full Papers)
11:30 - 12:10 Poster Session
12:10 - 12:20 Closing
Full Papers (Oral)
- Deep Metric Transfer for Label Propagation with Limited Annotated Data, Bin Liu (Tsinghua University), Zhirong Wu (Microsoft), Han Hu (Microsoft), Stephen Lin (Microsoft)
- Task-Discriminative Domain Alignment for Unsupervised Domain Adaptation, Behnam Gholami (Rutgers University), Pritish Sahu (Rutgers University), Minyoung Kim (Samsung AI Center), Vladimir Pavlovic (Rutgers University)
- Zero-Shot Semantic Segmentation via Variational Mapping,Naoki Kato (The University of Tokyo), Toshihiko Yamasaki (The University of Tokyo), Kiyoharu Aizawa (The University of Tokyo)
- Retro-Actions: Learning 'Close' by Time-reversing 'Open' Videos,Will Price (University of Bristol), Dima Damen (University of Bristol)
Full Papers (Spotlight + Poster)
- Enhancing Visual Embeddings through Weakly Supervised Captioning for Zero-Shot Learning, Matteo Bustreo (Istituto Italiano di Tecnologia), Jacopo Cavazza (Istituto Italiano di Tecnologia), Vittorio Murino (Istituto Italiano di Tecnologia)
- ProtoGAN: Towards Few Shot Learning for Action Recognition, Sai Kumar Dwivedi (Mercedes-Benz R&D India), vikram gupta (Mercedes-Benz R&D India), Rahul Mitra (Indian Institute of Technology Bombay), Shuaib Ahmed (Mercedes-Benz R&D India), Arjun Jain (Indian Institute Of Technology Bombay)
- Bayesian 3D ConvNets for Action Recognition from Few Examples, Martin de la Riva (University of Amsterdam), Pascal Mettes (University of Amsterdam)
- Input and Weight Space Smoothing for Semi-supervised Learning, Safa Cicek (UCLA), Stefano Soatto (UCLA)
- Picking groups instead of samples: A close look at Static Pool-based Meta-Active Learning, Ignasi Mas (Universitat Politècnica de Catalunya), Veronica Vilaplana (Technical University of Catalonia (Universitat Politècnica de Catalunya), Ramon Morros (Universitat Politècnica de Catalunya)
- Meta Module Generation for Fast Few-Shot Incremental Learning, Shudong Xie (Institute for Infocomm Research), Yiqun Li (Institute for Infocomm Research), Dongyun Lin (Institute for Infocomm Research), Tin Lay Nwe (Institute for Infocomm Research), Sheng Dong (Institute for Infocomm Research)
- Adversarial Joint-Distribution Learning for Novel Class Sketch-Based Image Retrieval, Anubha Pandey (Indian Institute of Technology Madras), Ashish Mishra (Indian Institute of Technology Madras), Vinay Kumar Verma (Indian Institute of Technology Kanpur), Anurag Mittal (Indian Institute of Technology Madras)
- Weakly Supervised One Shot Segmentation, Hasnain Raza (KIT), Mahdyar Ravanbakhsh (University of Genova), Tassilo Klein (SAP), Moin Nabi (SAP)
- Object Grounding via Iterative Context Reasoning, Lei Chen (Simon Fraser Univeristy), Mengyao Zhai (Simon Fraser University), Jiawei He (Simon Fraser University), Greg Mori (Simon Fraser University)
- Zero-shot Hyperspectral Image Denoising with Separable Image Prior, Ryuji Imamura (The University of Kitakyushu), Tatsuki Itasaka (The University of Kitakyushu), Masahiro Okuda (The University of Kitakyushu)
Extended Abstracts (Poster)
- Dense Parts-based Descriptors for Ingredient Recognition, James Hahn (Georgia Institute of Technology), Michael Spranger (Sony)
- Federated Learning Based Data Distillation and Augmentation for Improving the Performance of MobileNet-V2, Brijraj Singh (Indian Institute of Technology Roorkee), Durga Toshniwal (Indian Institute of Technology Roorkee)
- Multi-Source Policy Aggregation in Heterogeneous and Private Environmental Dynamics, Mohammadamin Barekatain (Technical University of Munich), Ryo Yonetani (OMRON SINIC X), Masashi Hamaya
- Adaptive Confidence Smoothing for Generalized Zero-Shot Learning, Yuval Atzmon (Bar-Ilan University, NVIDIA Research), Gal Chechik (Bar Ilan University)
- Few-Shot Learning Using Class Augmentation in Metric Learning, Susumu Matsumi (Meijo University), Keiichi Yamada (Meijo University)
- Zero-shot Video Retrieval using a Large-scale Video Database, Kazuya Ueki (Meisei University), Takayuki Hori (SoftBank Corp.)
- Seeing Many Unseen Labels via Shared Multi-Attention Models, Dat B Huynh (Northeastern University), Ehsan Elhamifar (Northeastern University)
- Adaptive Gating Mechanism for Identifying Visually Grounded Paraphrases, Mayu Otani (CyberAgent Inc.), Chenhui Chu (Osaka University), Yuta Nakashima (Osaka University)
- Construction of a Multi-modal Model of Pancreatic Tumors by Integration of MRI and Pathological Images using Conditional Cycle α-GAN, Tomoshige Shimomura (Nagoya Institute of Technology), Mauricio Kugler (Nagoya Institute of Technology), Tatsuya Yokota (Nagoya Institute of Technology), Chika Iwamoto (Kyushu University), Kenoki Ohuchida (Kyushu University), Makoto Hashizume (Kyushu University), Hidekata Hontan (Nagoya Institute of Technology)
- Tree trunk diameter and species estimation using a stereo camera, deep learning and image processing technique, Kenta Itakura (University of Tokyo), Fumiki Hosoi (University of Tokyo)
- SpiderNet: A Modular Approach to Unify Multimodal Modeling, Sanny Kim (Minerva Schools at KGI)
- Zero-Annotation Plate Segmentation Using a Food Category Classifier and a Food/Non-Food Classifier, Wataru Shimoda (The University of Electro-Communi-cations), Keiji Yanai (The University of Electro-Communications)


Professor, University of Amsterdam
Title: Localizing concepts, the few-shot way
Abstract: Learning to recognize concepts in image and video has witnessed phenomenal progress thanks to improved convolutional networks, more efficient graphical computers and huge amounts of image annotations. Even when image annotations are scarce, classifying objects and activities has proven more than feasible. However, for the localization of objects and activities, existing algorithms are still very much dependent on many hard to obtain image annotations at the box or pixel-level. In this talk, I will present recent progress of my team in localizing objects and activities when box- and pixel-annotations are scarce or completely absent. I will also present a new object localization task along this research direction. Given a few weakly-supervised support images, we localize the common object in the query image without any box annotation. Finally, I will present recent results on spatio-temporal activity localization when no annotated box, nor tube, examples are available for training.

We invite original research papers and extended abstracts. All submissions should be anonymized, formatted according to the template of ICCV 2019.
Research Papers (4-8 pages excluding references) should contain unpublished original research. They will be published in the ICCV workshop proceedings, and will be archived in the IEEE Xplore Digital Library and the CVF.
Extended Abstracts (2 pages including references) about preliminary work or published work will be archived on this website.
Please submit papers via the submission system (https://cmt3.research.microsoft.com/MDALC2019).

Research Paper Submission: August 2nd (11:59 PM, Pacific Time), 2019
Extended Abstract Submission: August 26th (11:59 PM, Pacific Time), 2019
Due to several requests, we have decided to extend the deadline for submission.
Workshop Paper Submission: July 26th, 2019
Notification: August 22nd (Research Papers), September 5th (Extended Abstracts)
Camera-ready: August 29th (Research Papers), September 12th (Extended Abstracts)
Workshop: October 27th AM at the same venue as ICCV 2019 in Seoul, Korea.


Tokyo Tech
AIST 
OSX
UTokyo

Tokyo Tech
NII
EURECOM
CityU
This workshop is supported by JST ACT-I (JPMJPR16U5).

concepts-ws@googlegroups.com